九月除了看 H.264,还看了一本好书:《程序员的自我修养:链接、装载与库》。对这本书我只想说一句话,相见恨晚。
看完这本书之后,结合本科阶段学习的程序设计(C++)、汇编、编译原理、计算机组成原理、计算机体系结构、操作系统这几门课程,我总算对“我们编写的 C/C++ 代码是怎么一步步在电脑上跑起来的”这个问题有了一个宏观的认识。当然,细节和深入之处想靠这一本书甚至一门课程就完全掌握是不可能的,但有了全局的宏观认识,深入钻研就不会不见森林,只是时间问题了。
通过这本书,我力图梳理以下四个问题:
- 编译:如何把平台无关的 C/C++,翻译为平台相关的机器指令?
- 链接:跨模块调用函数、访问变量时,如何确定(符号的)地址?
- 装载:如何建立起可执行文件、虚拟地址、物理地址三者的映射关系?
- 执行:机器指令如何执行?
其实总结下来,也就是一句话:编译、链接、装载、执行,都是怎么回事?
本文是我对上述几个问题的理解和总结,不足之处欢迎指正。当然,即便写得不错,原书还是要读的 :)
编译
通常我们在进行 C++ 开发时,“编译”的过程(即 g++ 命令)主要做下面四件事情:
- 预处理程序:宏定义展开,头文件展开;
- 编译:生成汇编代码;
- 汇编:生成目标文件(机器指令);
- 链接:生成可执行文件或库文件;
所以 g++ 实际上把编译和链接这两件事都为我们做了,这里我们分开探究,其中编译和汇编就是《编译原理》所讲的编译过程了。
编译在把源语言(C/C++)编译为目标语言(机器指令)的过程中,通常包括以下几个步骤:
- 词法分析;
- 语法分析;
- 语义分析;
- 中间代码生成和优化;
- 目标代码生成和优化;
下面我们以这行简单的代码为例,总结一下编译的过程。
array[index] = (index + 4) * (2 + 6);
首先我们要扫描源代码文本内容,分割为一个个记号(Token),例如 array, [, +, 2, ;。分割过程可以利用有限状态机实现,我们可以从头编写代码实现一个词法分析程序,也可以利用一个叫做 lex 的程序,编写词法规则配置,自动生成扫描器代码。
得到了 Token 之后,我们要进行语法检查,比如 index + 4 是合法的加法语法,index +-*/ 4 则是非法的语法。语法分析过程采用上下文无关文法和下推自动机实现,如果语法检查没有问题,最终我们会把 Token 以树的结构组织起来,叫做抽象语法树(Abstract Syntax Tree, AST)。例如下图:
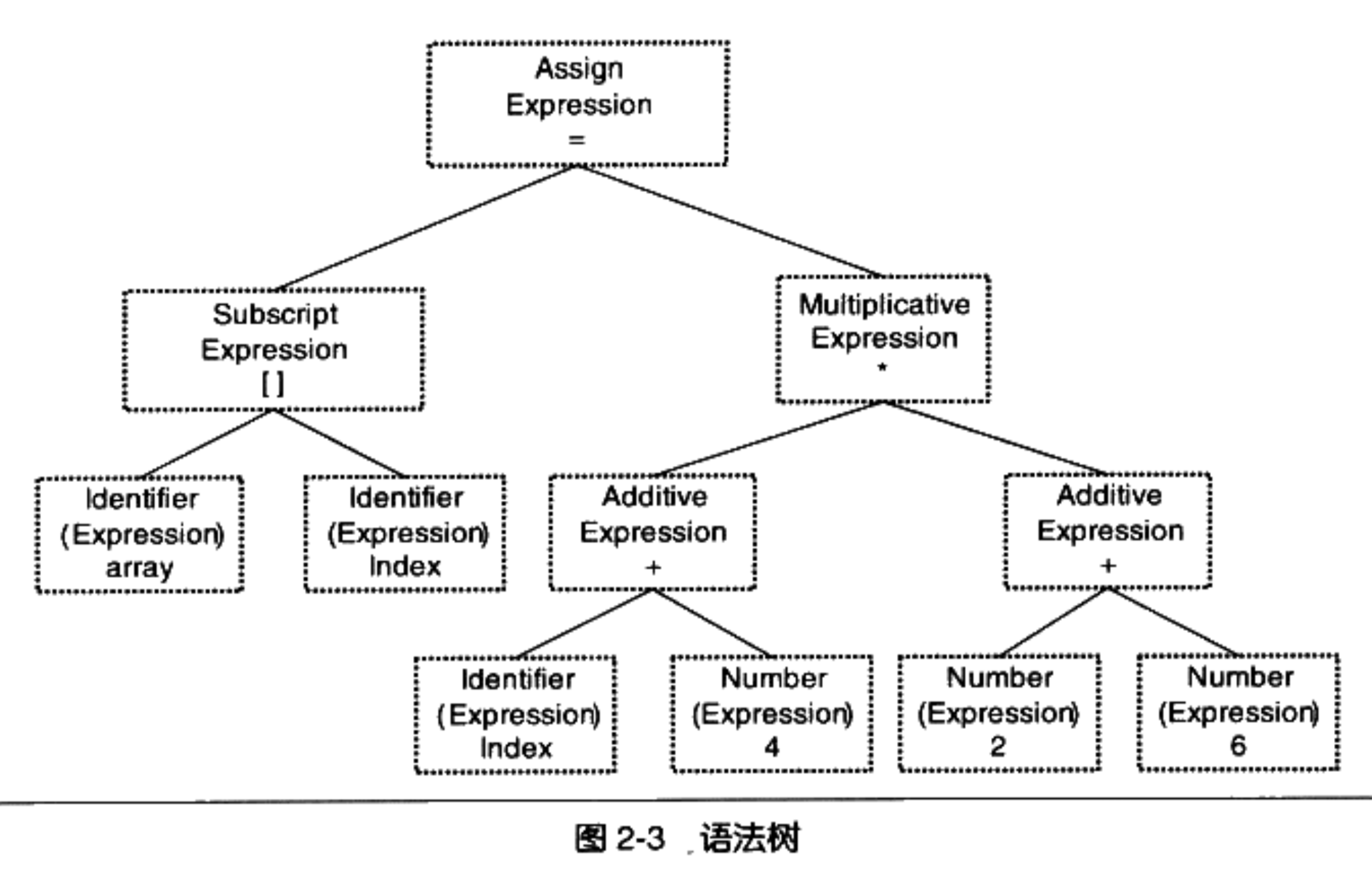
和词法分析类似,我们可以从头编码实现,也可以利用另一个叫做 yacc 的程序,编写语法规则配置,自动生成语法分析器代码。
语法检查只保证代码符合语法规则,但却不能保证语义正确,比如这里并没有定义 array 和 index 是什么,显然是不正确的。在编译期进行的语义分析都属于静态语义分析,通常包括声明和类型的匹配,类型的转换。处理完毕后,我们为 AST 的每个节点加上类型信息,如下图所示:
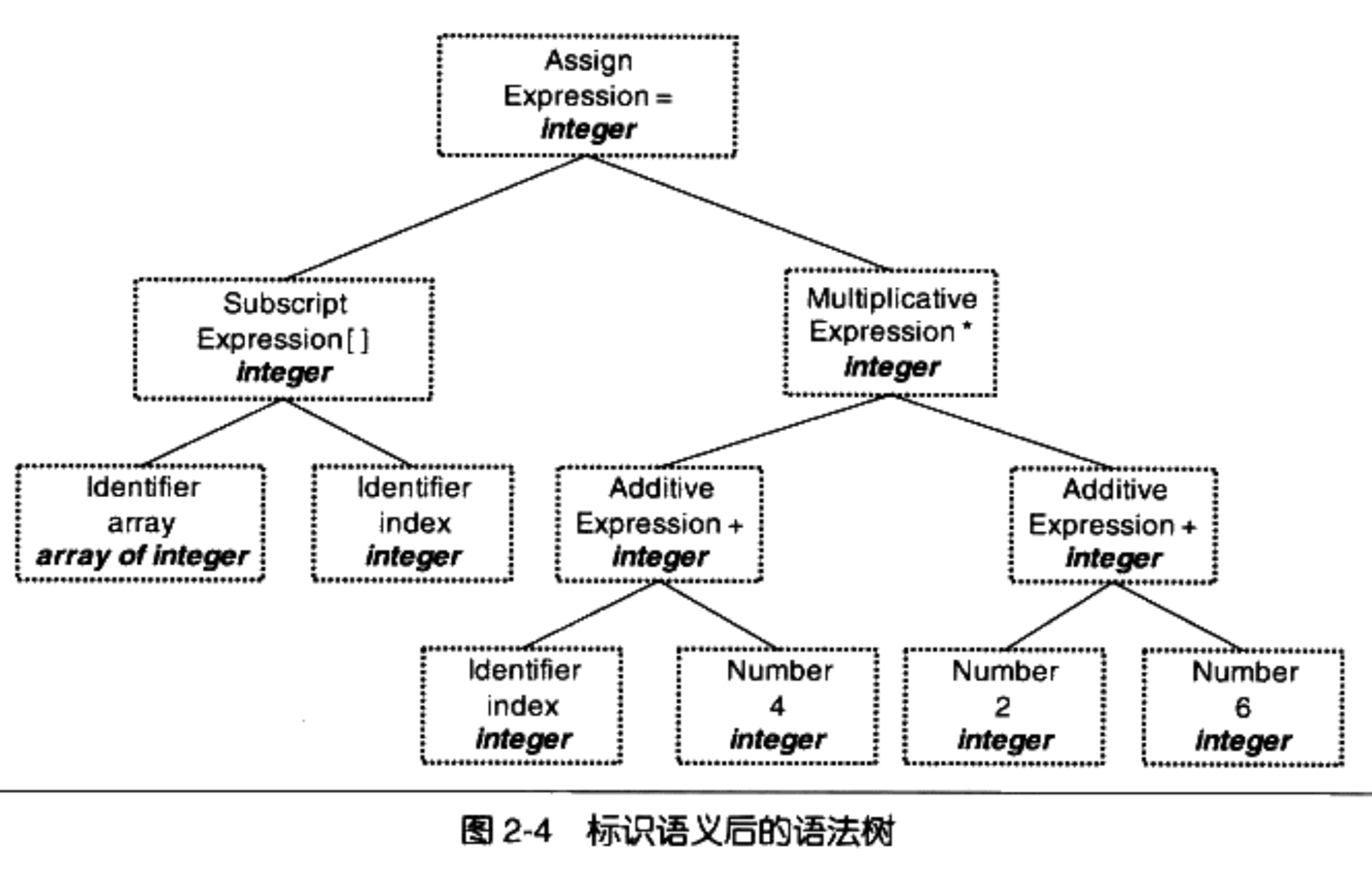
语义分析完成之后,生成目标代码(C++ 的目标代码就是机器指令)之前,我们通常会先把 AST 翻译为一种中间的表示形式,便于进行代码优化(比如 2 + 6 可以直接替换为 8)。这种中间的表示形式我们称之为中间代码,常见的形式有三地址码,中间代码的语法和 AST 的结构有一一对应关系。
最后我们把中间代码翻译为目标代码,同样,目标代码的语法和中间代码的语法也有一一对应关系。
至此,我们的编译过程就完成了,前面的问题想必大家已经有了答案:我们通过词法分析、语法分析、语义分析、中间代码生成和优化、目标代码生成和优化,把平台无关的高级语言,翻译为平台相关的机器指令。当然这里只是一个极简的总结,感兴趣的朋友可以阅读相关书籍。
这个仓库是清华计算机系《编译原理》课程大作业的资料,分为四个部分:词法分析和语法分析、语义分析、中间代码生成、中间代码优化。每个部分是一个单独的 Eclipse 项目,有详细的 README 文档,项目的代码结构相当优雅(经过数任助教多年锤炼),感兴趣的朋友可以把玩。
链接
前面我们搞清楚了编译就是把源码翻译为机器指令(01),但编译结果是怎么保存的?另外,代码量/工程规模大了之后,分模块组织代码是很有必要的,各个模块是独立编译的,多个模块如何合并?
我们先简要了解一下编译的输出文件——目标文件——的格式:
- 源码编译出来的包括机器指令代码、数据;
- 链接时需要的相关信息:符号表,调试信息,字符串等;
- 不同的信息按类型分段存储;
- 代码段:源码编译出来的机器指令,名为
.code或.text; - 数据段:已初始化的全局变量和局部静态变量数据,名为
.data; - BSS 段:未初始化的全局变量和局部静态变量,名为
.bss;这个段只是在段表里面记录了这些变量的总内存大小,文件后面并不存在这样一个段,至于这么大的应占内存空间是怎么构成的,则记录在符号表中; - 符号表:记录目标文件的符号信息,包括符号名字、符号值、符号大小等;
- 重定位表:记录目标文件中编译期无法确定地址的符号信息;
- 其他段;
- 代码段:源码编译出来的机器指令,名为
- 总的来说是两种段:程序指令(代码段)和程序数据(数据段,BSS);
- 分开存储,可以分别设置访问权限,指令只读,数据可读写;
- 提高程序的局部性,提高 CPU 缓存命中率;
- 同一份指令,多个进程共享,只占用一份内存;
再次声明,上面这段总结无比简略,不了解的朋友一定要阅读原书。
了解了目标文件的格式之后,我们面临的就是链接过程的主要任务了:合并目标文件。链接分为静态链接和动态链接,前者是在运行之前就把链接的工作做好,后者则是在运行时按需执行链接的工作。下面我们先总结静态链接的过程。
链接主要包括空间和地址分配、符号决议、重定位。链接完毕后,数据访问、指令跳转的目标虚拟地址就都确定了。
链接器首先扫描输入的目标文件,计算输出文件各段大小,合并同类段,分配虚拟地址。再根据重定位表(记录哪些指令需要调整、如何调整)和符号表(记录所有的符号及地址),确定编译时无法确定的符号地址,修改机器指令,这一步可以概括为“把什么修改为什么”。如果最后仍有符号无法确定地址,就报告“undefined reference”错误。
这里也再总结一下,编译结果保存在目标文件中,链接时通过空间和地址分配、符号决议、重定位,确定跨模块调用函数、访问变量时符号的地址。
装载
链接完成之后,目标文件内的各个符号地址就都确定下来了,那运行时是不是直接使用这些地址呢?其实不是,因为多个程序的链接是独立的,它们分配的符号地址就很可能发生冲突。而且运行过程中,也不是整个程序一直驻扎在内存中,因为这样会造成内存的大量浪费。装载所做的事情就是解决这些问题。
大多操作系统都使用页映射的方式装载可执行程序,装载过程大致分为三步:
- 创建进程的虚拟地址空间,实际上是创建虚拟地址(程序中所使用的地址)到物理地址(内存硬件的地址)的映射数据结构(页目录),用于后续保存映射关系;
- 读取可执行文件头,建立虚拟地址空间与可执行文件的映射关系;
- 将 CPU 指令寄存器设置为可执行文件的入口,启动运行;
到这里有的朋友可能会想,我们还只是建立了各种映射关系,但是并没有做实际的载入操作呀,怎么就能启动运行了呢?确实,现在还不能运行,因为还没有任何页面被加载到了内存中,所以就会立即触发一次页错误:如果页面没有载入到内存,就会暂停执行,操作系统把对应的可执行文件内容加载到内存,把该页面虚拟地址和物理地址的映射关系保存在页目录中,再恢复执行。页面加载之后,我们就可以正常执行了。
至此我们就知晓了装载是如何建立起可执行文件、虚拟地址、物理地址这三者的映射关系的了,页错误处理是核心,而联结这三者的纽带则是虚拟地址(Virtual Memory Address, VMA)。
执行
执行过程这里我总结两点,一是程序运行时的内存布局,二是函数调用过程。
程序运行时内存布局如图所示:
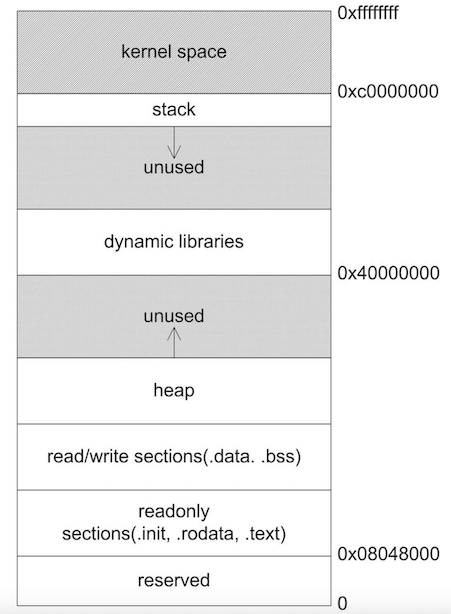
一个进程的虚拟地址空间大致可以分为这几种:代码,数据,堆(可向上/高地址扩展),栈(可向下/低地址扩展)。
其中栈是函数调用的核心,i386 中,栈顶由 esp 寄存器保存。栈内保存了一次函数调用所需要维护的信息,称之为栈帧(stack frame)或活动记录(activate record),其中包括:
- 函数的参数和返回地址;
- 保存的上下文:包括在函数调用前后需要保持不变的寄存器;
- 临时变量:非静态局部变量,编译器生成的其他临时变量;
- esp 指向栈顶,即栈帧的顶部,ebp 指向函数返回地址 + 4,被称为帧指针(frame pointer);
栈帧布局如下图所示(按照函数调用的标准流程来说,寄存器和局部变量的位置应该反了):

函数调用的标准流程如下(用汇编代码表示):
push ebp
mov ebp, esp
sub esp, x
[push reg1]
...
[push regn]
;函数实际内容
[pop regn]
...
[pop reg1]
mov esp, ebp
pop ebp
ret
了解了函数调用的流程之后,我们会发现,一次函数调用要想成功完成,函数的调用方和被调用方对函数如何调用必须要有着统一的理解,例如它们双方都一致地认同函数的参数是按照某个固定的方式压入栈内,这种统一的理解(共同的约定)就叫做调用惯例,它包括以下三方面:
- 参数的传递顺序和方式;
- 栈的维护方式(弹出参数);
- 名字修饰(name mangling)的策略;
总结
正如我在我需要知道:H.264 中所说:限于篇幅,本文无法把涉及到的概念都描述清楚,没有相关基础的读者需要查阅很多专业资料,而有相关基础的读者其实未必需要这样一篇总结文章,因此本文对于我梳理自己的思路意义更大,敬请谅解。