两年多前,我发布了我需要知道:H.264 一文,限于篇幅,当时没有对具体的句法元素做任何总结。
原本我想把每一层的各个句法元素简略过一遍的(实际也这么做过),但奈何完全无法涵盖细节,而众多句法元素罗列一遍实在无法脱离堆砌之嫌,所以索性删了个干净。感兴趣的朋友强烈建议阅读原书,或者 H.264 SPEC,至于从事视频编解码相关工作的朋友,则一定要对句法和语义烂熟于胸了。
这次,为了给 H.265 解析 QP 做好准备,我就以解析 QP 为主题,先回顾一下 H.264 的相关句法元素,并仔细研读了 WebRTC 解析 H.264 码流 QP 值的相关代码。
今天先把 H.264 的相关内容分享给大家,首先我们看一个解析句法元素必须具备的基础内容。
本文内容基于 201906 版本的 H.264 spec,以及 M79 分支的 WebRTC 源码。
描述子 descriptor
下面这个列表摘自《新一代视频压缩编码标准:H.264/AVC(第2版)》:
- ae(v): 基于上下文自适应的二进制算术熵编码;
- b(8): 读进连续的 8 个比特;
- ce(v): 基于上下文自适应的可变长熵编码;
- f(n): 读进连续的 n 个比特;
- i(n)/i(v): 读进连续的若干比特,并把它们解释为有符号整数;
- me(v): 映射指数 Golomb 熵编码;
- se(v): 有符号指数 Golomb 熵编码;
- te(v): 截断指数 Golomb 熵编码;
- u(n)/u(v): 读进连续的若干比特,并将它们解释为无符号整数;
- ue(v): 无符号指数 Golomb 熵编码;
下面这段解释也摘自《新一代视频压缩编码标准:H.264/AVC(第2版)》:
描述子都在括号中带有一个参数,这个参数表示需要提取的比特数。当参数是 n 时,表明调用这个描述子的时候会指明 n 的值,也即该句法元素是定长编码的。当参数是 v 时,对应的句法元素是变长编码,这时有两种情况:i(v) 和 u(v) 两个描述子的 v 由以前的句法元素指定,也就是说在前面会有句法元素指定当前句法元素的比特长度;除了这两个描述子外,其它描述子都是熵编码,它们的解码算法身能够确定当前句法元素的比特长度。
Golomb 熵编码
关于 Golomb 编码的原理详解,可以阅读 Golomb 和 Exp-Golomb 编码原理及实现这篇文章,不过关于这篇文章我有如下几处点评:
- 该文章讲「Golomb-Rice 编码」时,提到「取 r 的二进制位的低 log2(m) 位作为 r 的码字」,我这里再展开解释一下:其实 r 比 m 小,那 r 的二进制表示本就不会超过 log2(m) 位;比如 m = 8,则 r 最大也就是 7,那二进制就是
0b111,即最多 3 位,log2(8) 也就是 3; - 该文章讲「0 阶 Exp-Golomb 编码」时,提到「对于非负整数 N,其在编号为 m 的组内的充要条件是:
2^m − 1 <= N <= 2^(m+1) − 1」,此处应有误,充要条件当是2^m − 1 <= N < 2^(m+1) − 1,即前闭后开区间; -
该文章讲「0 阶 Exp-Golomb 编码」时,也提到「取 offset 二进制形式的低 m 位作为 offset 码元」,这里我也再展开解释一下:offset 是偏移量,
0 <= offset < 2^m(看图或根据 m 的计算公式,都可以推出这个结论),所以 offset 的二进制表示最多也就是 m 位;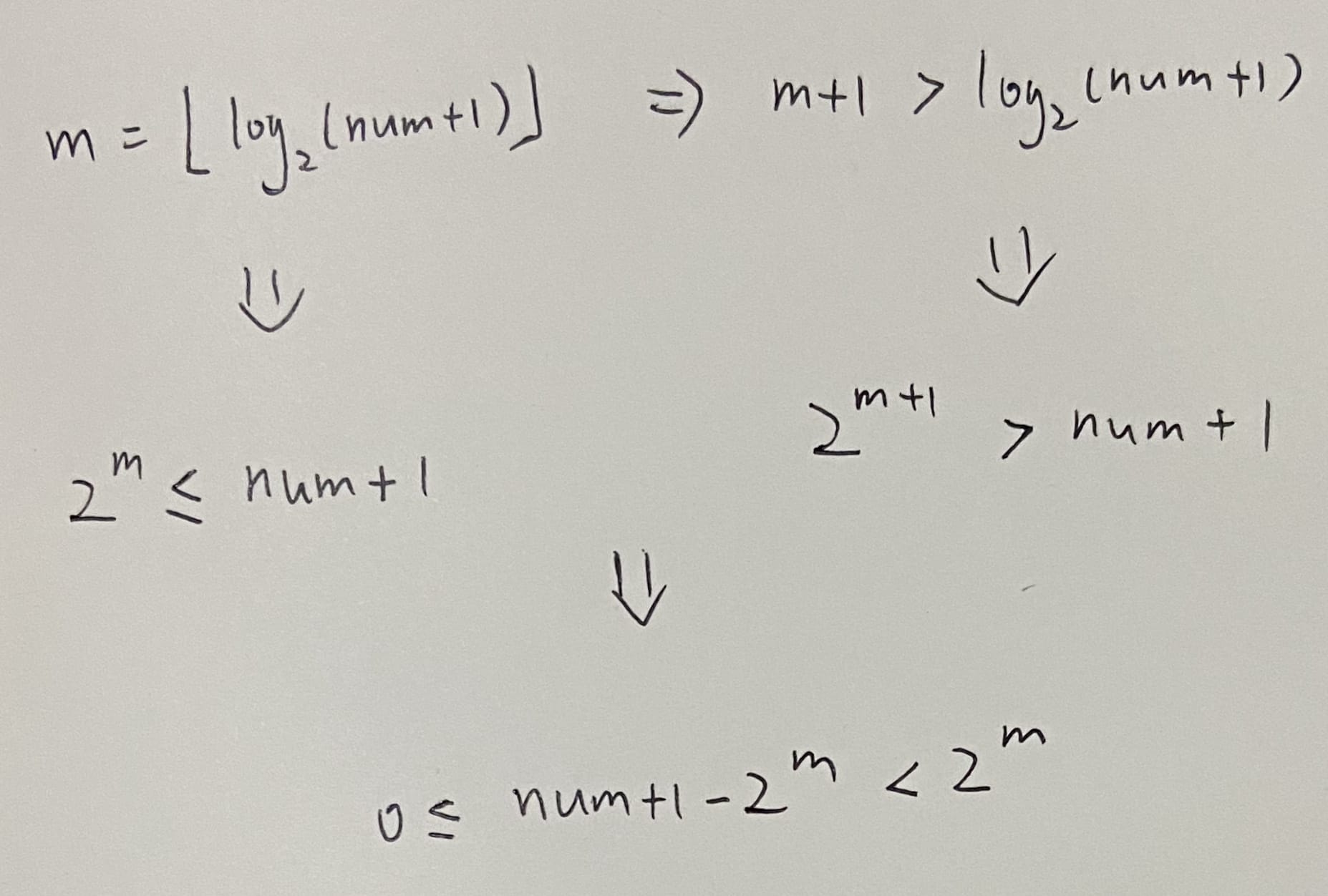
Golomb 编码原生只支持无符号数,ue(v) 直接使用即可,se(v) 需要把数字按照 0, 1, -1, 2, -2... 的规则编号,再对编号进行 Golomb 编解码。
me(v) 的思路也类似,把各种组合编号,再对编号进行 Golomb 编解码。te(v) 我在 spec 里没有看到使用,也没有看到详细说明。
解析 QP
WebRTC 解析 H.264 QP 的代码位于 common_video/h264/h264_bitstream_parser.cc 中,调用 ParseBitstream 传入 H264 码流进行解析,再调用 GetLastSliceQp 获取最后一个 slice 的 QP 值。
主体逻辑是解析出 PPS 中的 pic_init_qp_minus26,以及记录最后一个 slice 的 last_slice_qp_delta,则 parsed_qp = 26 + pic_init_qp_minus26 + last_slice_qp_delta。
这里我们以解析 SPS/PPS/AUD/SEI 之外的 NALU(也就是 slice)的代码为例,感受一下 H.264 码流解析的过程。
首先看下 slice header 的句法元素:

截图左边是类 C 语言的伪代码,表明解码逻辑。中间的 C 这一栏,是用于 slice 分区的,全称为 Categories,2 表明在 A 区,3 表明在 B 区,4 表明在 C 区(spec 里我也看到了 5,但 spec 里明明说的是其他取值都未定义);有的句法可能在 Categories 这一栏有多个数字,就表明在多种分区里面都会用到这个句法。右边的 descriptor 就是指明前文所述的 descriptor 了。
slice 分区本文不讨论。
下面是解析它的代码:
H264BitstreamParser::Result H264BitstreamParser::ParseNonParameterSetNalu(
const uint8_t* source,
size_t source_length,
uint8_t nalu_type) {
if (!sps_ || !pps_) // (1)
return kInvalidStream;
last_slice_qp_delta_ = absl::nullopt;
const std::vector<uint8_t> slice_rbsp = // (2)
H264::ParseRbsp(source, source_length);
if (slice_rbsp.size() < H264::kNaluTypeSize)
return kInvalidStream;
rtc::BitBuffer slice_reader(slice_rbsp.data() + H264::kNaluTypeSize, // (3)
slice_rbsp.size() - H264::kNaluTypeSize);
// Check to see if this is an IDR slice, which has an extra field to parse
// out.
bool is_idr = (source[0] & 0x0F) == H264::NaluType::kIdr; // (4)
uint8_t nal_ref_idc = (source[0] & 0x60) >> 5;
uint32_t golomb_tmp; // (5)
uint32_t bits_tmp;
// first_mb_in_slice: ue(v)
RETURN_INV_ON_FAIL(slice_reader.ReadExponentialGolomb(&golomb_tmp)); // (6)
}
要点如下:
- 由于 slice header 句法元素的解析需要用到 SPS/PPS,所以如果没有解析出 SPS/PPS,就只能返回错误了;
- 调用
H264::ParseRbsp函数去掉码流中对起始码(001或0001)的转义处理,关于起始码转义,可以阅读我的我需要知道:H.264 这篇文章; rtc::BitBuffer类实现了前文各种 descriptor 的解码逻辑,由于 NALU 的第一个字节(NALU header)无需解析,所以可以跳过;- 这个判断逻辑虽然执行结果没有问题,但逻辑上有瑕疵,因为 NALU type 其实是首字节的低 5 位,所以应该和
0x1F做按位与操作才对,但是由于H264::NaluType::kIdr这个类型的取值是 5,不会超过低 4 位,所以执行结果不会出错,此处可以改为其实bool is_idr = H264::ParseNaluType(source[0]) == H264::NaluType::kIdr;,如果担心多一层函数调用,则可以把ParseNaluType函数增加inline关键字nalu_type已经作为参数传了进来… - 这里我们关心的其实只有 QP 相关的字段,其他的字段取值都不重要,但由于 QP 字段的位置我们无法知道,只能按照句法元素顺次解析到 QP 所在的字段,WebRTC 的代码里就用
golomb_tmp和bits_tmp去容纳不关心的字段的值; - 查看句法元素,我们知道首先是
ue(v)格式的first_mb_in_slice,那就调用封装好的ReadExponentialGolomb即可,里面的实现就是前文所述的 Golomb 解码逻辑;
我们接着看代码:
// slice_type: ue(v)
uint32_t slice_type;
RETURN_INV_ON_FAIL(slice_reader.ReadExponentialGolomb(&slice_type));
// slice_type's 5..9 range is used to indicate that all slices of a picture
// have the same value of slice_type % 5, we don't care about that, so we map
// to the corresponding 0..4 range.
slice_type %= 5;
// pic_parameter_set_id: ue(v)
RETURN_INV_ON_FAIL(slice_reader.ReadExponentialGolomb(&golomb_tmp));
if (sps_->separate_colour_plane_flag == 1) { // (1)
// colour_plane_id
RETURN_INV_ON_FAIL(slice_reader.ReadBits(&bits_tmp, 2)); // (2)
}
// frame_num: u(v)
// Represented by log2_max_frame_num bits.
RETURN_INV_ON_FAIL(
slice_reader.ReadBits(&bits_tmp, sps_->log2_max_frame_num)); // (3)
要点如下:
- 这里句法元素判断了 SPS 的
separate_colour_plane_flag变量,代码也要进行同样的判断; colour_plane_id是u(2)类型,调用ReadBits消费两个比特即可;frame_num是u(v)类型,它是变长编码,其比特数为 SPS 的log2_max_frame_num_minus4加 4,这个规则在 spec 的「7.4.3 Slice header semantics」一节中有描述;代码上,WebRTC 在解析 SPS 时,就已经把 minus4 的逻辑考虑进去了,log2_max_frame_num就已经是加 4 后的值;
接下来的句法元素如下:

代码上都是老套路,这里就不展开了,唯一值得一提的就是 pic_order_cnt_lsb 的比特数为 SPS 的 log2_max_pic_order_cnt_lsb_minus4 加 4,这一规则也在 spec 的「7.4.3 Slice header semantics」一节中有描述。
接下来的句法元素也都是老面孔:
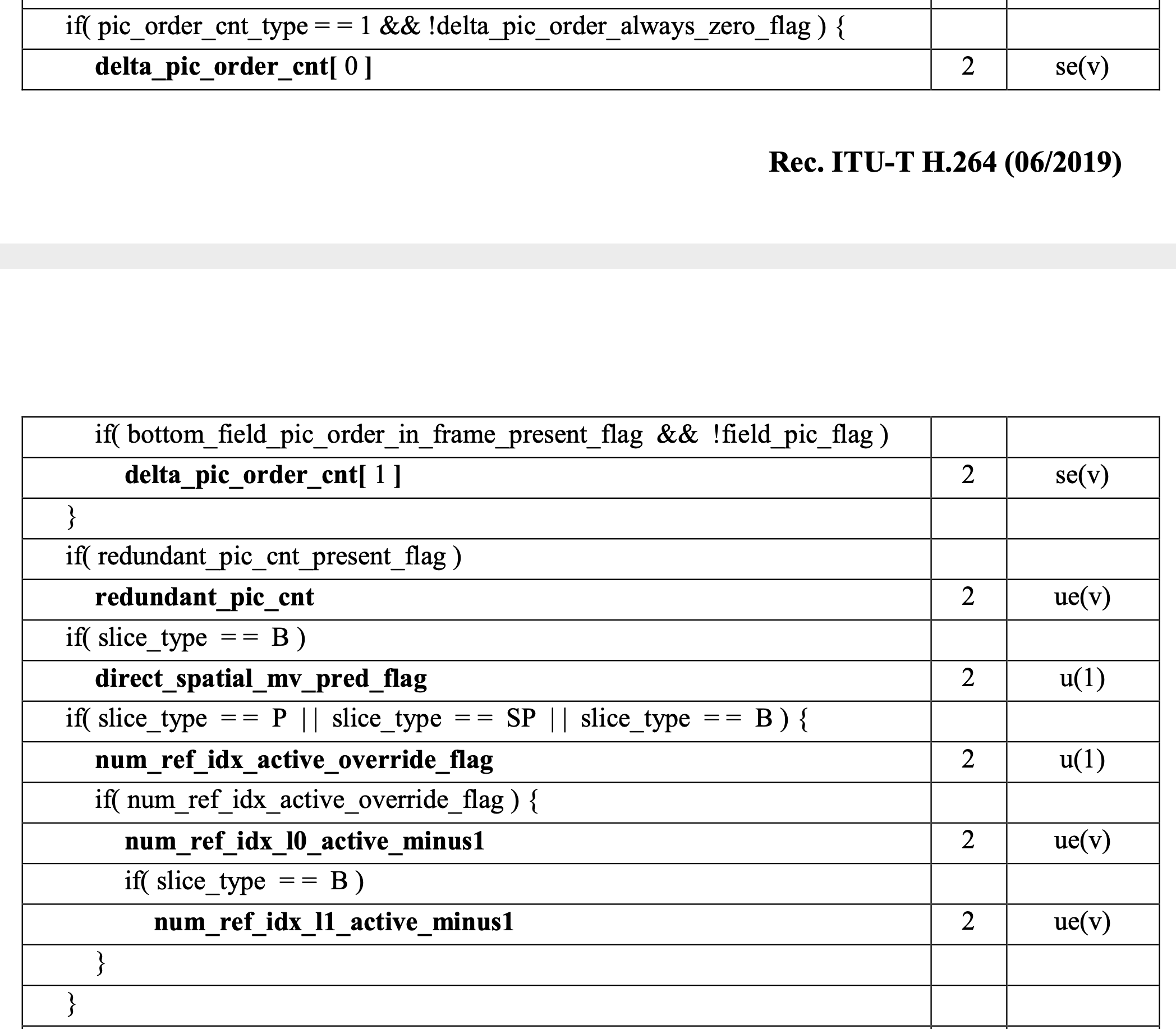
再接下来,终于见到目标了:

不过不要高兴得太早,所谓望山跑死马,虽然我们看到 slice_qp_delta 了,但中间实际还隔了不少东西:ref_pic_list_mvc_modification, ref_pic_list_modification, pred_weight_table 和 dec_ref_pic_marking,都是需要进一步展开的句法元素。
所以回过头来继续看代码:
// assume nal_unit_type != 20 && nal_unit_type != 21:
if (nalu_type == 20 || nalu_type == 21) { // (1)
RTC_LOG(LS_ERROR) << "Unsupported nal unit type.";
return kUnsupportedStream;
}
// if (nal_unit_type == 20 || nal_unit_type == 21)
// ref_pic_list_mvc_modification()
// else
{ // (2)
// ref_pic_list_modification():
// |slice_type| checks here don't use named constants as they aren't named
// in the spec for this segment. Keeping them consistent makes it easier to
// verify that they are both the same.
要点如下:
- WebRTC 暂不支持 20 和 21 这两个 NALU 类型,这两个类型在最初的 spec 里都是保留类型,是后来扩展的类型,想必会编出这两个类型的编码器也不多,所以 WebRTC 就不支持它们了;
- 所以就可以跳过
ref_pic_list_mvc_modification的处理,只处理ref_pic_list_modification了;
那么我们就来看看 ref_pic_list_modification 的句法元素:

其实没有太多新东西,只不过多了循环处理,不过这岂能难倒大家?所以我就不展开代码了。
那接着往后看:
// TODO(pbos): Do we need support for pred_weight_table()?
if ((pps_->weighted_pred_flag && (slice_type == H264::SliceType::kP ||
slice_type == H264::SliceType::kSp)) ||
(pps_->weighted_bipred_idc == 1 && slice_type == H264::SliceType::kB)) {
RTC_LOG(LS_ERROR) << "Streams with pred_weight_table unsupported.";
return kUnsupportedStream;
}
// if ((weighted_pred_flag && (slice_type == P || slice_type == SP)) ||
// (weighted_bipred_idc == 1 && slice_type == B)) {
// pred_weight_table()
// }
if (nal_ref_idc != 0) {
// dec_ref_pic_marking():
嗨,又往前跳了一大步:pred_weight_table 也不用支持,直接解析 dec_ref_pic_marking。
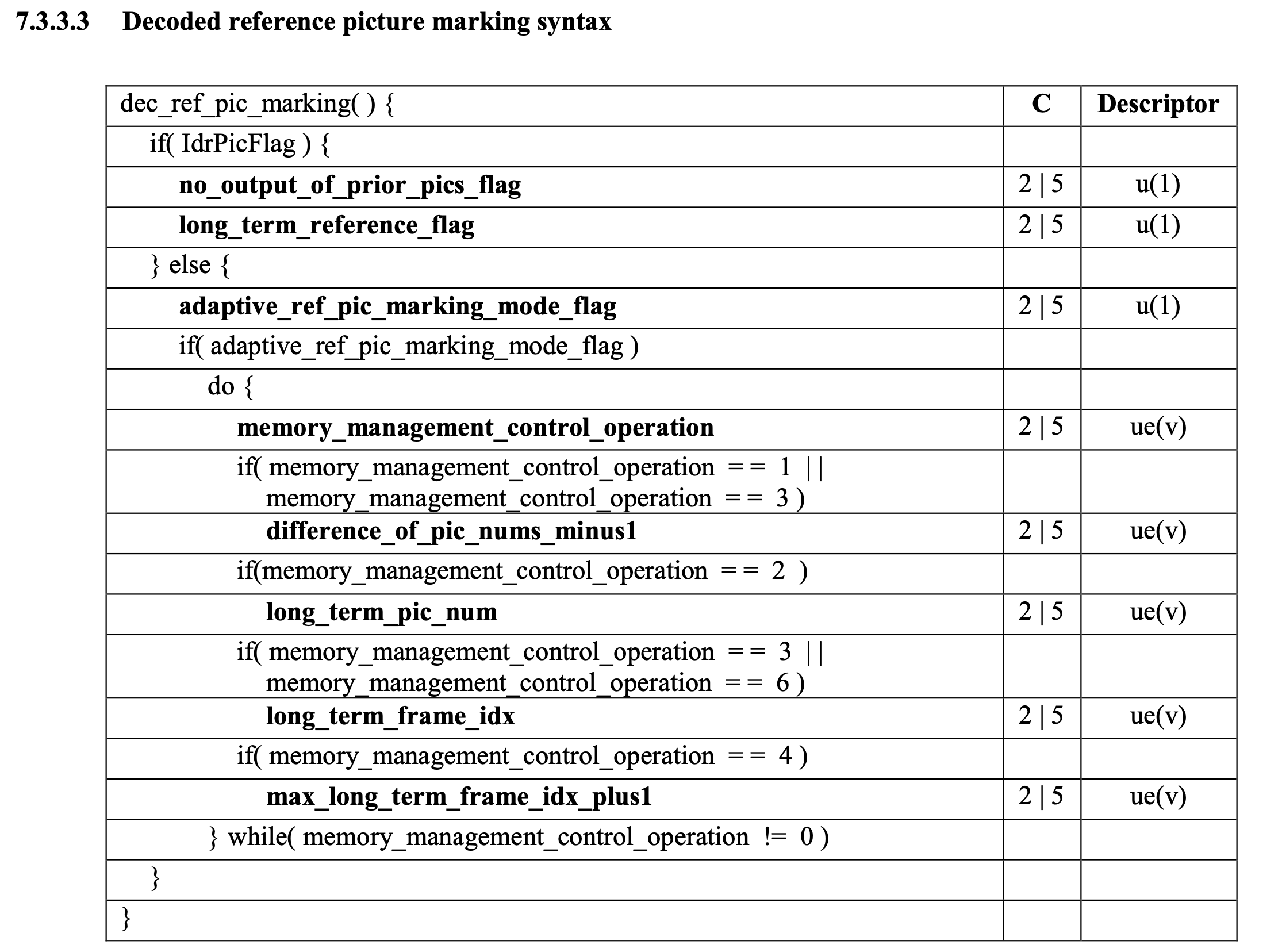
也都是老朋友了,一切尽在不言中 :)
总结
原本以为这块内容很复杂,有点畏难情绪,但其实静下心来看,也不过如此嘛 :)
欢迎大家加入 Hack WebRTC 星球,和我一起钻研 WebRTC。