自从 HackWebRTC 书稿交给出版社编辑后,很多事情的推进都显得有些劲头不足,「给 AvConf 增加 Linux 平台支持并对服务器做压测」这件事,基本拖了整个四月,但还是没搞定。所以在 51 假期开始前,我就构思了一个 Hackathon,准备在这个出不了门的 51 一口气搞定一个事情。从待办事项列表中看来看去,最后确定了目标:给 AvConf 写一个日志自动处理工具。
这个事情在当下也是有作用的,之前有几次看日志的过程,光是梳理基本流程、看 stats,就要花费很多时间,当时就初步构思了这个事情,并记录到了待办事项中。不过在启动这件事之前,我还决定先把 AvConf Linux 收个尾,即便现在退出时会 crash,也要先将就着测一测。
AvConf Linux 对服务端做压测
然而真等我测起来,才发现是个大坑,最初我是通过一个进程内创建多个 AvConf 对象(SDK 主类,提供加入、离开房间等接口)来进行测试,这样测试程序写起来简单一些,但跑着跑着总是会在中途 crash,各种位置更新 state 时都会报 “Must be newly frozen”。只创建一个 AvConf 对象和手机连,测试是没问题的。于是我想着那就 fork 子进程吧,每个子进程一个对象,但跑起来还是 crash。
而且在 Linux 上跑完整 WebRTC 流程(视频不包括采集、渲染、编码、解码),CPU 占用奇高,不比 KITE 强,所以果断放弃了。
不过一开始看到这么高的 CPU 占用率时,我还是 profiling 了一番的,使用的是 Linux 自带的 perf + brendangregg/FlameGraph,使用步骤为(参考了 CPU Flame Graphs):
git clone https://github.com/brendangregg/FlameGraph
perf record -a -F 1000 --call-graph dwarf ./LinuxExample
perf record -a -F 1000 -g ./LinuxExample
perf script | ../FlameGraph/stackcollapse-perf.pl > out.perf-folded
../FlameGraph/flamegraph.pl out.perf-folded > perf-kernel.svg
--call-graph dwarf 和 -g 结果略有不同,可以都试试。
我在一台 AWS t3.medium 上跑了一下只推一路流的情况,出来的结果如下(对应关系已经记不清了,Chrome 右键在新标签页打开,可以进行交互操作):


可以看到,56% 在 network_thread SRTP 加密,25% 在 Kotlin worker 线程,这两块都不是一两行代码就能动的,而目前又没有紧迫需求,所以就先这样吧。
我在群里分享了这个 profiling 结果后,忘篱大神还私信了我一个优化方向:
SRTP 打开汇编优化能降低不少,enable-openssl,可以看 srs 的编译脚本。
不过先不搞了 :)
AvConf 日志自动处理
好了,正餐终于要开始了,时间才到 1 号下午两点多,才半天工夫,问题不大。
AvConf 使用了腾讯开源的 xlog 来打日志,所以需要先对日志文件进行解码,而如果以后做了日志上传,那还需要先对上传的压缩包进行解压,所以首先要有一个 LogLoader 类,负责解压、解码、读取。
然后是一个 LogPreProcessor 类,负责做日志内容的分割、关联、组织:
- 每个文件(peer)按 room 分割,不同文件通过 room 关联,输出按 room 组织的日志列表,即 room 列表;
- room 的主要信息就是 rid(房间号),peer 的主要信息则是 uid, device id, sdk version 等;
- 这里有两种边界情况需要考虑,一个文件可能有多个用户的日志(切换账号),一个用户可能出现在多个文件中(换设备登录),不过在一次加入房间的过程中,这两种情况应该都不会发生;
- 最终日志的组织方式为:多个 room 按时间顺序组织,一个 room 包含多个 peer,一个 peer 包含多个 attendance(参会记录);
- 后来在实现的过程中,发现这个时间顺序不太好实现,各个设备的时钟不一致,需要服务端配合才能实现,所以就先忽略了;
日志经过预处理后,下一步就是对每个 room 里的情况进行分析了,这个分析逻辑日后很可能还会有新增,所以我就定义了一个 LogProcessor 接口,LogAnalyzer 会有一个 LogProcessor 列表,挨个进行处理,这样后续增加新的处理逻辑,就新建 LogProcessor 子类即可,原有逻辑不用动。
LogProcessor 的处理结果为:
- 主要流程事件:加入,加入成功,起推流,推流成功,推流 ICE 断连,RS FAIL,重试,起收流,收流成功,收流 ICE 断连,离开;
- 推收流 stats:视频采集、发送帧率;视频码率,包括设给编码、编码输出、发送、估计可用发送带宽;发送音频数据时长;视频接收、解码帧率;视频接收码率,估计可用接收带宽;接收音频数据时长;等等;
上面提到的三大类,都是「幕后人员」,为了能很直观地看到上述处理的结果,「台前代表」的设计着实花费了一番工夫,1 号晚上和 2 号上午,都在做调研和实验。
最开始我还以为 Allure 可以满足我的需求,但仔细看了看文档,才发现压根不是那么回事,Allure 是和各种测试框架对接,没有自定义生成报告的接口。类似的 reporting framework 也没有找到能用的,所以基本确定要自己写网页画图表了。
最开始我的设想是这些事件按照时间顺序一字排开,并且每个 attendance 的非收流事件,都作为主线事件,而收流事件则拉出一条支线,比如这样:

其实这个图是后来补画的,最开始确实想得没这么清晰。
之所以要竖排,主要是考虑线可能比较长,横着会受限于浏览器宽度,同时图中的事件也不只是圆形和方形,还得标出事件名称。但在调研的过程中,我死活没找着能加 marker 且能 invert axis 的 line chart(关键词拿走不谢 :)),无奈只能选择横排了。另外,为了简化上述 LogProcessor 列表的处理逻辑,不必对添加事件的顺序做出要求,所以我也就去掉了拉支线时的那条分支线,这样不管图表里的点顺序如何,最终画出来的也就是一条直线。
最终我选择的是 CanvasJS,免费 license 还在申请中,希望能通过。
不过这里我再推荐一个调研过程中发现的好东西:Observable,注意不是 RxJava 的 Observable,而是一个用 JS 写 notebook 的网站,D3.js 的例子都是用它来做的,非常棒!不过 D3.js 因为接口太偏底层,还得自己写 SVG,没有能拿来即用的 line chart,所以最终我没用它。
有了数据(假定 LogProcessor 已经写完了),也有了展示方式,怎么把它们对接起来呢?我选择的是 Apache FreeMarker 模板引擎,因为这个 LogAnalyzer 我是打算用 Kotlin 来写的,所以模板引擎就得选一个 Java 版本的了,而且 Apache 开源,靠谱。
至此,万事俱备,只欠代码了,经过一整天(24 - 8 = 16h)的 coding,第一期的功能就搞定了,效果如图(没管样式,所以丑了点)。
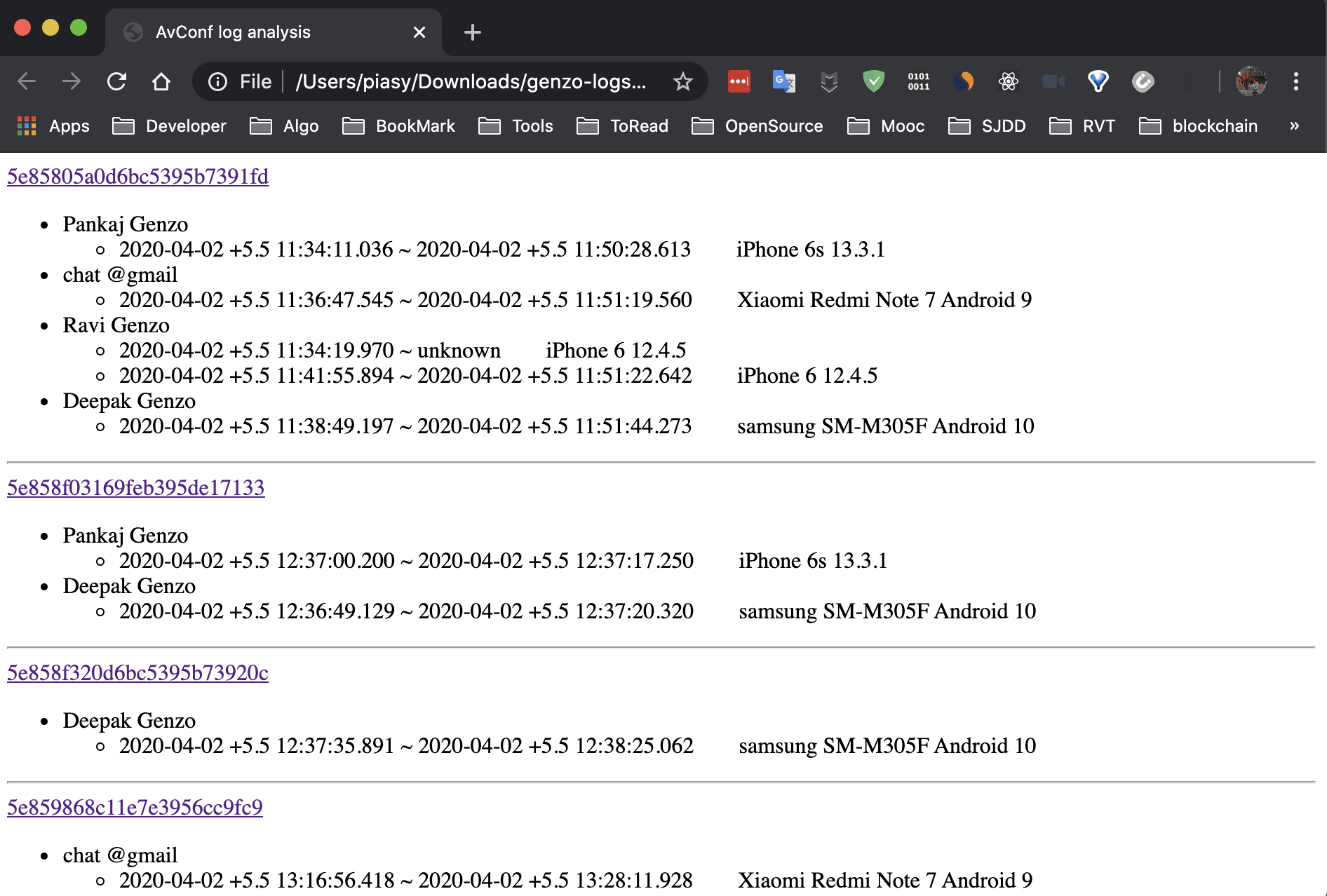
报告首页
room 页
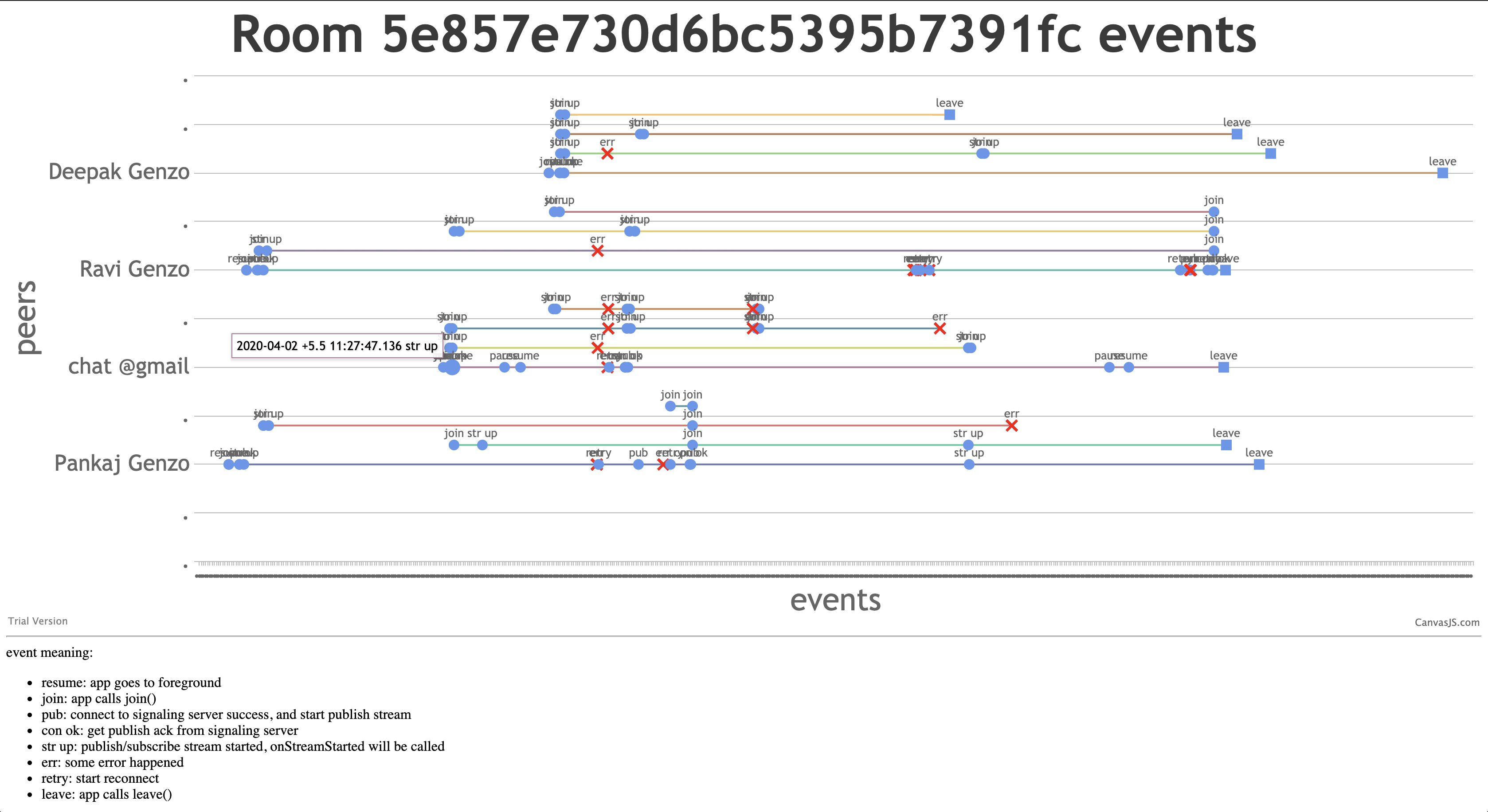
由于一些事件间隔很短,所以 marker 甚至 point 都重合了,不过通过移动光标,还是能在 tooltip 里面看到完整信息的。可以看到,这个 room 里问题很多,❌❌一堆。
stats 页
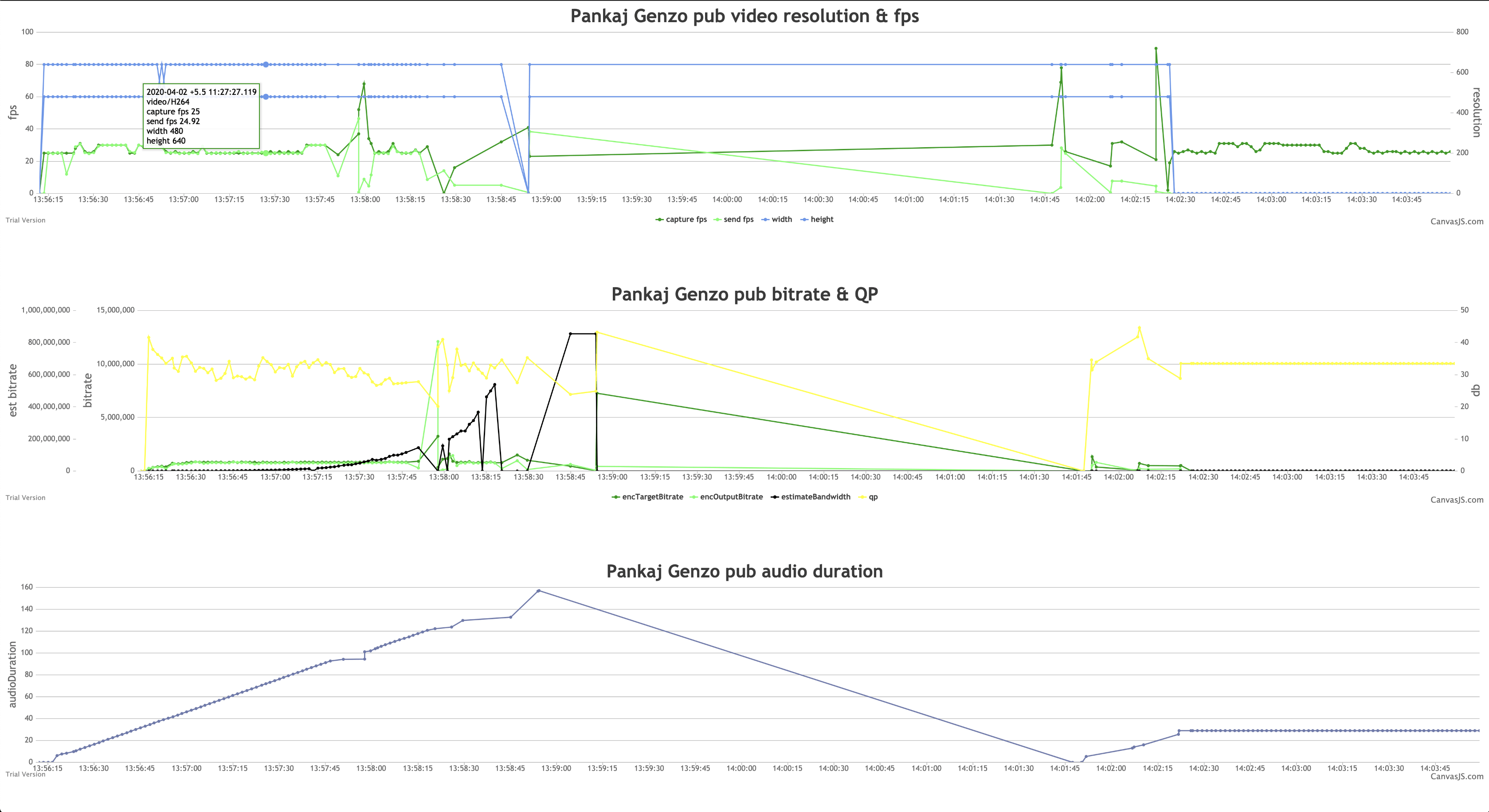
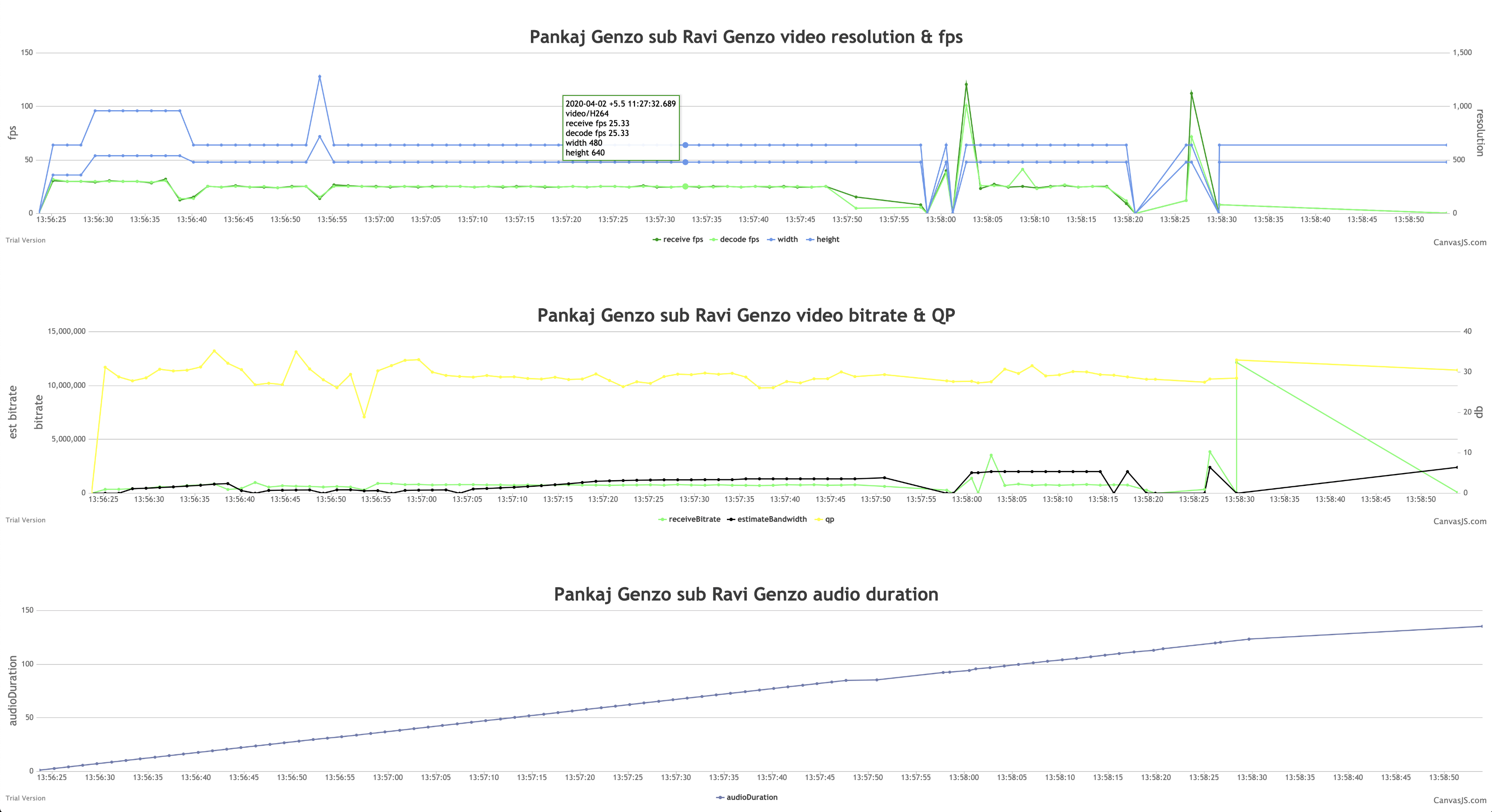
stats 也能体现出一些问题来。
总结
这种一口气搞定一件事的感觉还是很爽的,堪称畅快淋漓。
不过鉴于 51 还有两天,所以我打算继续把第二期做一下:做成一个 web 服务,这样对分析人员的环境就没有要求了。为此首先需要一个文件上传服务,然后调用 LogAnalyzer,并把报告网页放在静态文件服务器的路径下(比如 nginx),再做个重定向即可。似乎用 Python Flask 可以。
至于再下一步,就是日志文件自动上传、归档,按需选择日志文件、分析处理了,这一步就先不做了,需求不强烈,而且 51 也没时间了。
再会。
欢迎大家加入 Hack WebRTC 星球,和我一起钻研 WebRTC。