在 2017 年初,我报了一个 Udacity 的深度学习的纳米微学位课程,当时想着作为门外汉,面临网上海量的信息、教程,完全不知如何下手,就借助一下课程团队经过精挑细选、仔细编排之后的课程安排。当时学完觉得挺有收获,还准备写一些在安卓平台上应用深度学习的例子,不过没能实现(作为 Hello World 的 MNIST 手写数字识别写了一半),而是转向了 WebRTC,于是有了一系列的 WebRTC 文章,以及 HackWebRTCBook。
一转眼七年多过去了,深度学习发展演化出了大语言模型(LLM),并被众多公司认为是通往通用人工智能(AGI)的必经之路。在 LLM 火了一年多之后,最近我也开始了深入学习,今天就给大家带来第一篇分享。
入门学习资料
这两周看了很多入门学习资料,关于 LLM 介绍的、关于提示词工程(Prompt Engineering, PE)的,现在回头来看我觉得看两个就够了:Andrej Karpathy 的 Intro to Large Language Models 和吴恩达的 ChatGPT Prompt Engineering for Developers,其中遇到不懂的再专门搜索学习即可。
Intro to Large Language Models
这个演讲真的是非常好,讲得深入浅出,让人醍醐灌顶,建议大家认真学习。
这里我对第一部分简单总结几点:
- LLM 最核心的是神经网络(模型)的参数(权重)文件,比如 700 亿参数的模型,每个参数 2 字节(float 16),就有 140GB;运行神经网络所需要的代码则只需要几百行;
- 参数文件通过大规模训练(模型参数多、训练数据多、GPU 集群大、训练时间久)得到,这个过程叫预训练(Pretrain);
- 模型的基本任务,是根据训练数据中单词的概率分布,尝试生成单词(或者给定输入单词序列,预测下一个单词,或者叫续写),并不是回答问题,给模型输入问题,模型可能续写出更多的问题;
- 通过构造输入,让输入看起来像是一个待补充的文档,引导模型用续写的方式把回答补充出来,就可以让模型来回答问题了,实际上这个构造输入的过程,就是 PE 了;
- 对预训练模型,再使用一些“提问 - 回答”的数据集进一步训练,可以让模型能更好地完成回答问题的任务,这个过程叫有监督微调(Supervised Finetuning, SFT);
- 在很多情况下,比较多个答案哪个更好比直接生成答案更容易,基于这个经验,可以使用一些“多个答案 - 答案相对打分”的数据集,训练出一个奖励模型(Reward Model, RM),然后再把 RM 和 SFT Model 结合起来进行强化学习,最终得到的模型效果比 SFT Model 更好,这个过程叫基于人类反馈的强化学习(Reinforcement Learning with Human Feedback, RLHF);
听完第一部分,我立马想到了我在 3 月份和一位月之暗面的创始人同学聊天时,他给我讲 Kimi 能不停地自我学习、不需要人来教他,原来就是 RLHF 呀!当时觉得很神奇难以理解,模型自己学习,它怎么知道什么是对的/错的(或者好的/差的)?
不过这个疑问其实现在依然存在:根据 RM 训练集里的数据训练出的 RM,然后就用它来提升 SFT model 的效果,这个过程就像是让一个不怎么靠谱的老师,通过给我们打出不怎么靠谱的分数,来指导我们提升,就很神奇。
目前我的理解:
- 很多情况下,对比多个答案的好坏,比直接生成好答案要容易,这个确实符合常理,所以 RLHF 能改进效果;
- 训练 RM 的数据集,规模比 SFT 过程的数据集要大(在 InstructGPT 论文中有说明,SFT 数据集包含 13k prompts,RM 数据集则包含了 33k prompts),所以 RLHF 能改进 SFT 的效果;
- 就连神经网络本身能工作的可解释性都不是很清晰,所以 RLHF 能改进效果的可解释性也就不要强求了;
演讲后两部分关于 LLM 的未来和安全性的话题,我就不总结了,建议大家自行观看学习。
ChatGPT Prompt Engineering for Developers
这个迷你课程也非常实用,很多网上的 PE 文章,核心内容都来源于此。课程结合了几个具体的场景来进行讲授,而这几个具体场景,也正是 LLM 目前比较擅长的:总结,推理(观点/情绪/提取信息),转换(翻译),续写。对于逻辑要求较高的工作,LLM 还不是很擅长,或者说比较容易一本正经的胡说八道。
关于 PE,这里我也简要总结几点:
- 原则一:指令要清晰、具体;
- 使用分隔符,比如三个引号/反引号/横线(
""", ```,---),尖括号,xml 标签等等; - 要求模型给出结构化输出,比如 HTML,JSON 等;
- 告诉模型要检查执行任务的条件/假设是否满足,如果不满足就不要执行任务逻辑,而是给出一个错误提示;
- few-shot: 给出几个成功的示例,让模型可以学习;
- 使用分隔符,比如三个引号/反引号/横线(
- 原则二:给模型思考的时间(也就是 Chain of Thought, CoT);
- 显式给出完成任务的具体步骤;
- 让模型自己找出完成任务的步骤;
- 幻觉问题:模型可能会给出看上去正确实际上是瞎编的回答;可以让模型先找到相关信息,然后基于相关信息做出回答,这样能缓解幻觉问题;
-
没有一个放之四海而皆准的最佳提示词,我们需要结合自己的场景,通过持续迭代的方式来得到最佳提示词:
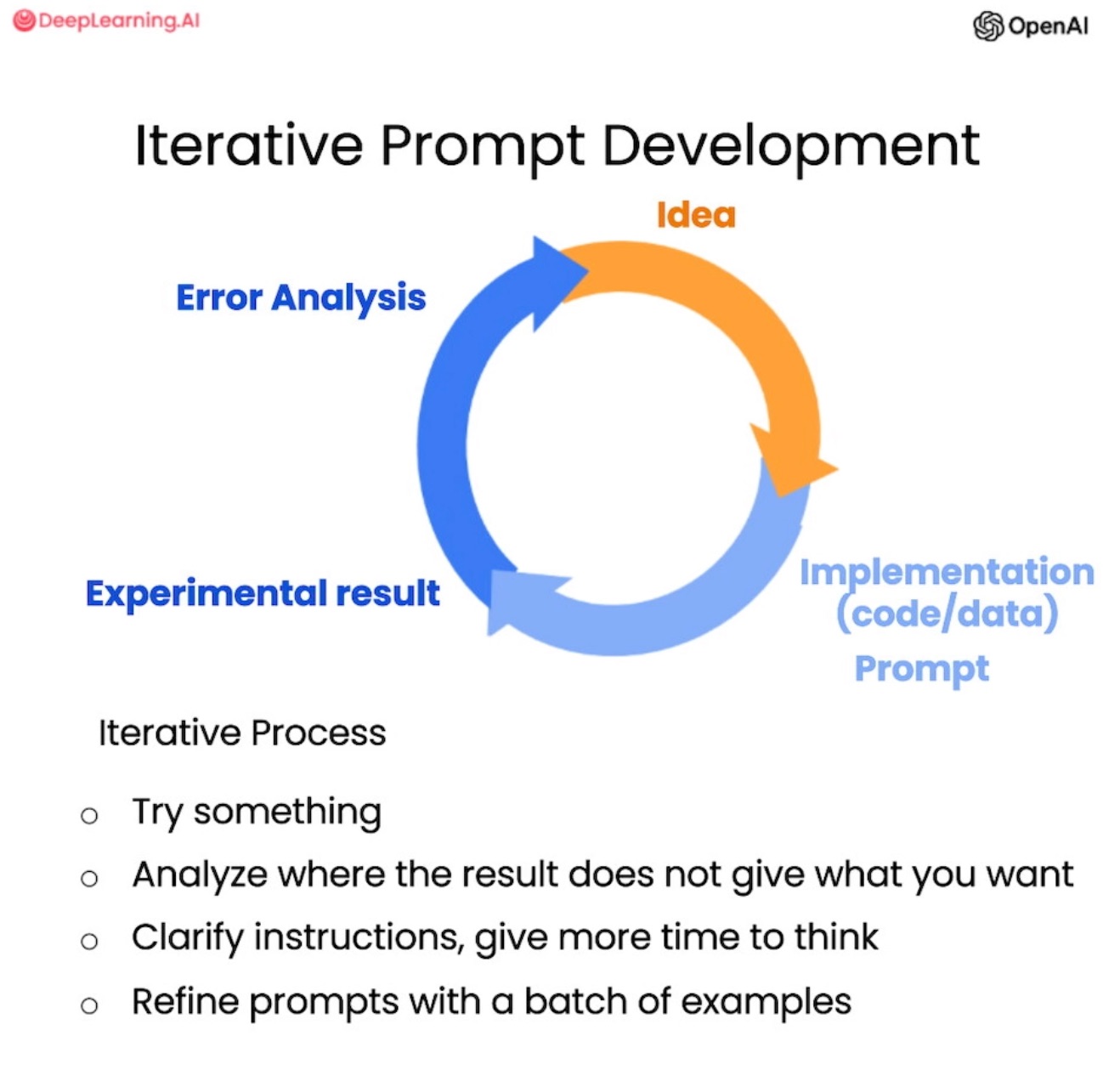
实操练习
学习了理论知识,接下来我们就进行一个实操练习:让 LLM 回答减法问题。
众所周知,LLM 不擅长数学运算,就让我们尝试看看最简单的减法运算,LLM 表现如何,然后尝试通过 PE 和 SFT 的方式,提升 LLM 的表现。
我们会使用火山引擎的方舟平台,用豆包大模型的基础版(Doubao-lite-4k)、Llama3 8b/70b 来完成这个练习。
平台使用
火山引擎账号注册、登录、实名认证后,打开火山方舟,可以看到有 50 万 token 免费额度,简直美滋滋。
我们将主要使用模型精调和评测任务,当然,我们也可以在模型广场体验一系列的豆包大模型,以及众多一站式解决方案,简直不要太方便。
测评
首先,我们进入到「测评任务 - 创建测评任务」,选择模型我们选 Doubao-lite-4k 的主线模型/Llama3 8b/Llama3 70b,在上传数据集的时候可以查看测评数据集格式说明:
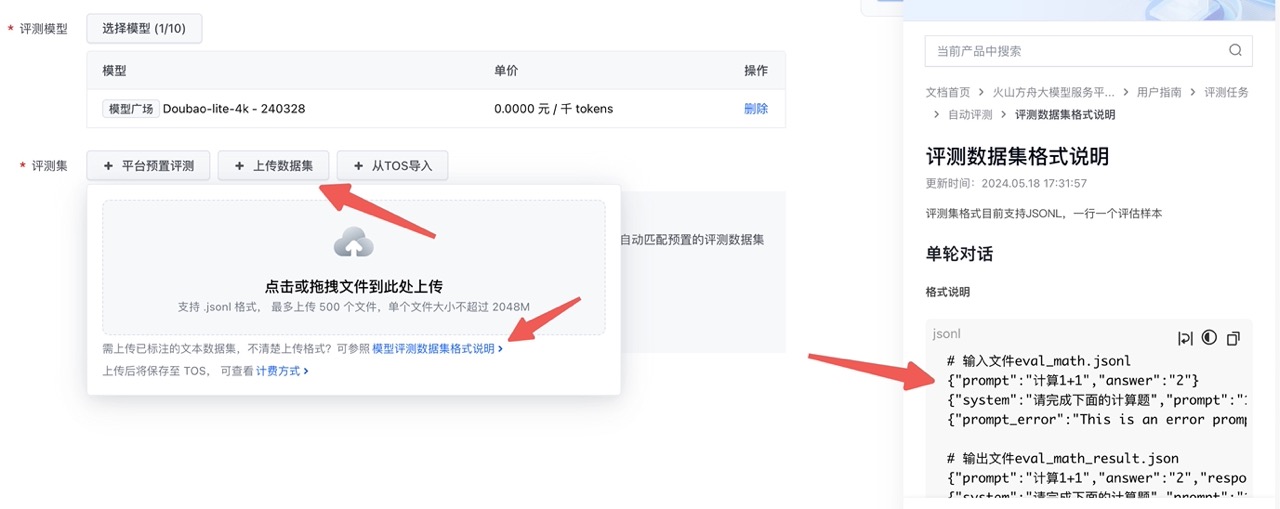
对于减法运算来说,写个小的 Python 脚本就可以轻松生成数据集:
import random
test_digits = [2, 5, 10, 20]
data_size = 1000
with open("LLM_minus_test_data.jsonl", "w") as f:
for i in range(0, data_size):
dx = test_digits[i * 4 // data_size]
x = int(random.random() * (10 ** dx))
dy = int(random.random() * dx) + 1
y = int(random.random() * (10 ** dy))
f.write('{"prompt":"请计算:%d - %d = ,直接返回计算结果","answer":"%d"}\n' % (x, y, x-y))
这里我们将使用 请计算:%d - %d = ,直接返回计算结果 这样的输入格式,分别生成最多 2/5/10/20 位的运算,并且预期模型直接给出结算结果。
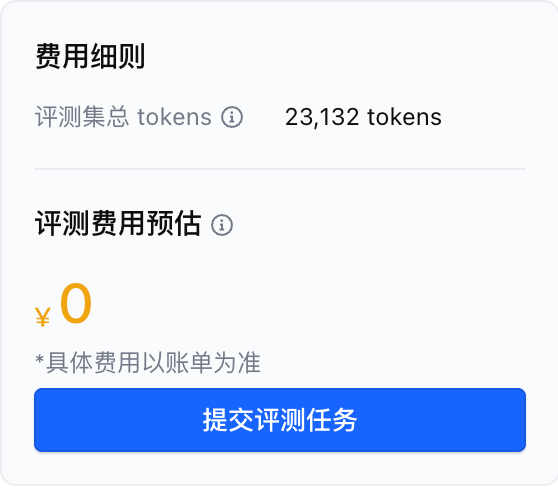
我生成的测评集有 2.3 万个 token,测评免费~
提交之后,经过一段时间的等待,三个模型的基础得分依次为 12.4、3、29.8 分:

可以看到,豆包基础版还是比 Llama3 8b 版本要强很多的,但比 70b 的版本还是差了不少。由此可见,参数量从 8b 增加到 70b,模型的能力强了近十倍。
Prompt 优化
运用我们上面学到的知识,对 Prompt 进行一些优化:
你是一个数学计算器,能计算两个数字的减法。
请直接返回计算结果,不要包含计算过程,也不要包含算式和等于号,直接给出结果的数字。
例子:
<input>请计算:29 - 68 = ,直接返回计算结果</input>
<output>-39</output>
<input>请计算:87 - 16 = ,直接返回计算结果</input>
<output>71</output>
<input>请计算:75 - 99 = ,直接返回计算结果</input>
<output>-24</output>
<input>请计算:32 - 7 = ,直接返回计算结果</input>
<output>25</output>
<input>请计算:35 - 2 = ,直接返回计算结果</input>
<output>33</output>
输入:
请计算:29 - 68 = ,直接返回计算结果
有几个要点:
- 定义角色
- 要求输出格式
- few-shot,给出了 5 个例子
- 分隔符:例子的输入输出用 xml tag 括起来
重新生成测评数据,再次测评,结果来到了 51.9、42、56.6 分:

都有显著的提升,模型之间的差距也没那么大了,可见 PE 还是最快速的优化手段。
SFT
但 PE 的优化效果毕竟有限,于是我们按照上面 Prompt 的格式,生成一些训练数据,对模型进行精调。
import random
test_digits = [2, 5, 10, 20]
data_size = 10000
with open("LLM_minus_SFT_train_data.jsonl", "w") as f:
for i in range(0, data_size):
dx = test_digits[i * 4 // data_size]
x = int(random.random() * (10 ** dx))
dy = int(random.random() * dx) + 1
y = int(random.random() * (10 ** dy))
f.write('{"messages": [{"role": "user", "content": "你是一个数学计算器,能计算两个数字的减法。\n请直接返回计算结果,不要包含计算过程,也不要包含算式和等于号,直接给出结果的数字。\n例子:\n<input>请计算:29 - 68 = ,直接返回计算结果</input>\n<output>-39</output>\n<input>请计算:87 - 16 = ,直接返回计算结果</input>\n<output>71</output>\n<input>请计算:75 - 99 = ,直接返回计算结果</input>\n<output>-24</output>\n<input>请计算:32 - 7 = ,直接返回计算结果</input>\n<output>25</output>\n<input>请计算:35 - 2 = ,直接返回计算结果</input>\n<output>33</output>\n输入:\n请计算:%d + %d = ,直接返回计算结果"}, {"role": "assistant", "content": "%d"}]}\n' % (x, y, x-y))
我分别生成了 1w、10w、100w 数据集,进行训练。训练参数不做调整,打开验证集开关并设置 10%。不过 100w 的训练数据,预估费用要 2700+ RMB,就先不训练了。
训练完成之后,再用上面同样的测评数据集进行测评,训练情况和测评结果如下:
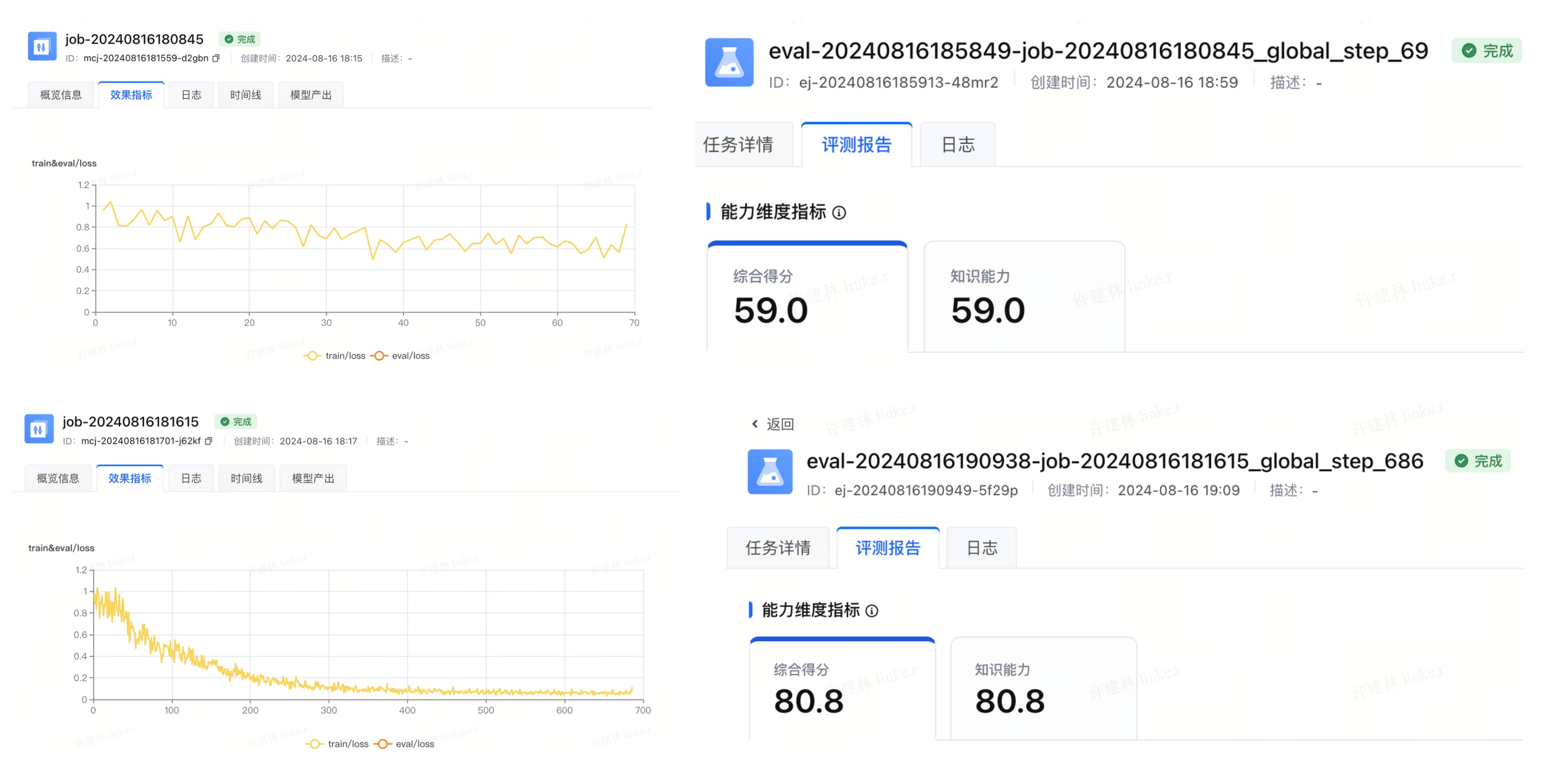
可以看到,1w 的训练数据还是太少了,loss 还远远没有收敛,10w 的训练数据则好了很多,loss 基本收敛到了 0.1 以内。测评结果也比较明显的反映了训练情况:1w 训练集 SFT 之后只提升到了 59 分,10w 训练集 SFT 之后则提升到了 80.8 分。
下载 80.8 分的测评结果分析看,各个位数的正确率为:
2: 1.00
5: 0.96
10: 0.86
20: 0.36
确实位数越多,正确率越低。LLM 的工作原理毕竟是基于概率分布的文本生成,位数太长的数字,在原始训练数据中就不是很常见,而且可能被分词为多个单词,因此很难完美地完成太长位数的数学运算。
但我们可以通过调用外部工具的方式,比如调用外部计算器,来让模型(或者说让机器人)能够完美胜任计算任务,下一篇,我将给大家分享这方面的内容,敬请期待~