本文是 Piasy 独立翻译,发表于 https://blog.piasy.com/AdvancedRxJava/,请阅读原文支持原创 https://blog.piasy.com/AdvancedRxJava/2017/03/19/comparison-of-reactive-streams-part-1/
原文 Comparison of Reactive-Streams implementations (part 1)。
介绍
Reactive-Streams 最近在并发/并行技术圈越来越知名,也出现了好几个不同的实现,最值得关注的包括:Akka-Streams,Project Reactor 和 RxJava 2.0。
在本文中,我将展示如何利用这些库实现简单的数据流,并且用 JMH 进行性能测试。为了对比的完整性,我还对 RxJava 1.0.14,Java 以及 j.u.c.Stream 进行了测试。
在第一部分中,我将用下面的测例,对比 4 个库的同步行为:
- 1 到 (1,1000,1,000,000)的
range; - 对(1)中的数据流使用
flatMap操作,把每个数据转换为只有一个数据的数据流; - 对(1)中的数据流使用
flatMap操作,把每个数据转换为有两个数据的数据流;
运行环境:
- Gradle 2.8
- JMH 1.11.1
- Threads: 1
- Forks: 1
- Mode: Throughput
- Unit: ops/s
- Warmup: 5, 1s each
- Iterations: 5, 2s each
- i7 4790 @ 3.5GHz stock settings CPU
- 16GB DDR3 @ 1600MHz stock RAM
- Windows 7 x64
- Java 8 update 66 x64
RxJava
我们首先看看 RxJava,添加 RxJava 1.x 的依赖:
compile 'io.reactivex:rxjava:1.0.14'
添加 RxJava 2.x 的依赖:
repositories {
mavenCentral()
maven { url 'https://oss.jfrog.org/libs-snapshot' }
}
compile 'io.reactivex:rxjava:2.0.0-DP0-SNAPSHOT'
遗憾的是,上述两个版本不能同时依赖,可以注释掉其中一个,或者使用我的 backport:
compile 'com.github.akarnokd:rxjava2-backport:2.0.0-RC1'
设置好依赖之后,我们看代码:
@Params({"1", "1000", "1000000"})
int times;
//...
Observable<Integer> range = Observable.range(1, times);
Observable<Integer> rangeFlatMapJust = range
.flatMap(Observable::just);
Observable<Integer> rangeFlatMapRange = range
.flatMap(v -> Observable.range(v, 2));
不同版本的 RxJava 代码是一样的,只是 import 包名不一样。
我们利用 LatchedObserver 接收数据,它可以在各个库的测试中复用:
public class LatchedObserver<T> extends Observer<T> {
public CountDownLatch latch = new CountDownLatch(1);
private final Blackhole bh;
public LatchedRSObserver(Blackhole bh) {
this.bh = bh;
}
@Override
public void onComplete() {
latch.countDown();
}
@Override
public void onError(Throwable e) {
latch.countDown();
}
@Override
public void onNext(T t) {
bh.consume(t);
}
}
由于数据流是同步的,所以我们这里实际上用不到 latch,只需要订阅即可:
@Benchmark
public void range(Blackhole bh) {
range.subscribe(new LatchedObserver<Integer>(bh));
}
让我们看看 1.x 和 2.x 的结果:
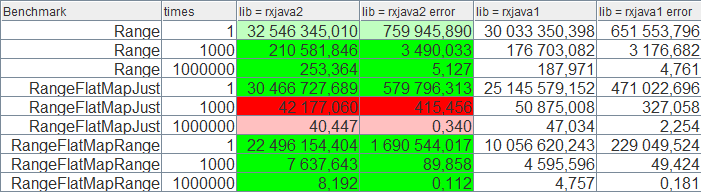
上面是我的 JMH 对比工具 的一张截图,它能把结果用不同的颜色展示出来:绿色表示比基准线要好,红色则比基准线差。浅色表示差距在 +/- 3%,深色表示在 +/- 10%。
本文所有的截图中,数字越大表示性能越好。把 times 和结果数字相乘,就得到了事件个数。在这幅图中,times = 1,000,000 时,发射了将近 253M 个数据。
我们可以看出,RxJava 2.x 性能高出了一截,但有两个 RangeFlatMapJust 的例子除外,为什么会这样?我们分析一下。
性能的提升来自于 RxJava 2.x subscribe() 的开销比 1.x 更小。在 1.x 中我们订阅时,Subscriber 会被包装为 SafeSubscribe,而且当 Producer 被设置时,会发生一次小的“仲裁”。据我所知,JIT 在 1.x 中会尽可能消除掉内存分配和同步操作,但这个仲裁操作无法被移除,这样就会多执行一些 CPU 指令。而在 2.x 中,没有任何包装以及仲裁。
性能更差的情形,则是由于两个版本使用的串行访问方式不同:1.x 使用的是基于 synchronized 的发射者循环,而 2.x 则是用的基于原子操作的队列漏。前者可以被 JIT 消除掉(因为这里是单线程测试),而后者则不能消除,所以每次发射数据都将有大约 17ns 的开销。我打算对 2.x 做一次全面的性能分析,所以这个问题不会存在太久。
总结一下,RxJava 在高性能和易用性方面都做得很好,为什么要提到易用性?请见下文。
Project Reactor
Project Reactor 支持 Reactive-Streams 规范,也提供了类似于 RxJava 的流式 API。
我之前简单测试了它的 2.0.5-RELEASE 版本,但现在我要用最新的版本进行测试:
repositories {
mavenCentral()
maven { url 'http://repo.spring.io/libs-snapshot' }
}
compile 'io.projectreactor:reactor-stream:2.1.0.BUILD-SNAPSHOT'
这样可以确保能够包含他们最新的性能提升。
测试代码看起来很相近:
Stream<Integer> range = Streams.range(1, times);
Stream<Integer> rangeFlatMapJust = raRange.flatMap(Streams::just);
Stream<Integer> rangeFlatMapRange = raRange
.flatMap(v -> Streams.range(v, 2));
注意 Streams.range() 的 API 发生了一点变化,2.0.5 中它接受的是 start+end 参数(闭区间),现在变成了 start+count,和 RxJava 的 range 一致。
我们仍用 LatchedObserver 接收数据,测试结果如下:
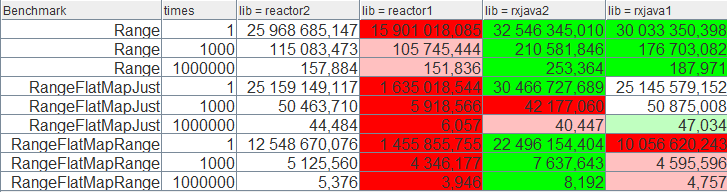
上图中,reactor2 代表了 2.1.0 snapshot,reactor1 代表了 2.0.5 release。显然 Reactor 通过减少操作符的开销(大约优化了 10 倍)极大地提升了性能。
但 RangeFlatMapJust 测试中有一个奇怪的现象:RxJava 1.x 和 Reactor 2.1.0 都比 RxJava 2.x 的性能要好,而且它俩性能差不多。why?
在 flatMap 操作符中,RxJava 1.x 是基于 synchronized 的发射者循环,在单线程时,可以被 JIT 移除,从而降低开销,2.x 则是基于原子操作的队列漏,在快路径上的两次原子操作无法被 JIT 移除。
那我们看看 Reactor 是怎么做的。它的 flatMap 是用 FlatMapOperator 实现的,而它的实现和 RxJava 2.x 几乎一致!甚至它们都有同样的 bug!
当然 bug 是玩笑,它们有几处细微的差别,所以我们重点关注快路径的差别,找出 Reactor 吞吐量高出 4~8M 的原因。
doNext() 看起来完全一样:如果数据源是 Supplier,那就直接取出数据,不用订阅,然后在 tryEmit() 中发射数据。
可能的 bug:如果这条路径发生了错误,进入到了 reportError(),那代码将会继续执行,Publisher 将会被订阅。
可能的 bug:在 RxJava 2.x 中,我们始终会在调用用户接口的时候用 try-catche 包起来,所以用户代码的错误都是就地处理的。而在 Reactor 的实现中,doNext 里面并没有这样做(有可能在调用链的上游某处做了处理)。
tryEmit() 几乎完全一样,但有一处至关重要的差别:它把请求做了打包处理,而不是逐个向上游请求。有意思!
if (maxConcurrency != Integer.MAX_VALUE && !cancelled
&& ++lastRequest == limit) {
lastRequest = 0;
subscription.request(limit);
}
在内部 Subscriber 的实现中,RxJava 2.x 和 Reactor 都实现了同样的打包逻辑(尽管上面的测例并没有体现这一点)。Project Reactor 干得漂亮!
在 RangeFlatMapRange 中,我们并没有进入快路径,Reactor 的性能稍逊一些,尽管它的 flatMap 实现是一样的。原因在于 Reactor 的 range 操作每秒就要少产生 100M 个数据。
沿着引用链条,我们发现了大量的包装和概括(generalization),但它们对每个 Subscriber 只会有一次,所以它在 times = 1000000 时不会是主要原因。
原因在于 Reactor 的 range() 实现类似于 RxJava 2.x 的 generator(例如 SyncOnSubscribe)。ForEachBiConsumer 看起来很简洁,但我依然能看出几处不足之处:
- 使用了原子操作,这让 JIT 优化的代码必须从缓存读取数据,而不能利用寄存器。requestConsumer 可以在循环之前先读到局部变量中。
- 尽可能多的使用
==或者!=操作,因为其他比较操作在 x86 中性能差一些。 - 原子递减操作比较耗时(~10 ns),它可以延后:一旦已知的请求数量已经处理完毕,我们可以先读取请求量,看看是否在我们处理的同时来了新的请求。如果有新的请求,那我们就可以继续发射,否则我们才从请求量中减去已经发射的数量。
RxJava 的 range 现在还没有实现后面的几点;HotSpot 的寄存器分配现在看起来还比较混乱:(x64 平台的)寄存器超量导致了太多的局部变量和性能下降。实现后面几点需要更多的局部变量,这有可能让性能更差。
总的来说,Reactor 在各个版本中已经越来越好了,尤其是当它采用了和 RxJava 2.x 相同的结构和算法之后 :)
Akka-Streams
我认为 Akka-Streams 是上述库中广告做得最多的。它背后是一家商业公司,而且移植自 Scala,它可能会有什么问题?
译者注:从这里我们可以看出作者对 Akka 有那么一点点鄙视。原文中作者写出 Akka 的测例也是费了半天功夫,甚至上 StackOverflow 提了问题,因为对 Scala 不熟,其中的曲折故事这里就不展开了,感兴趣可以阅读原文。
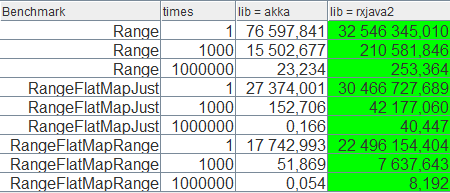
注意,由于 Akka 不支持同步模式,我们必须用各种办法使得可以测试,我们可以给结果乘以 5~10。
我也不知道这里是怎么回事,有些数据慢了 100x。
总结一下,我对 Akka-Streams 非常失望,为了运行一个简单的数据流,我不得不大费周章,而且性能上还任重道远。
Java 和 j.u.c.Stream
仅仅是作为参考,让我们看看纯用 Java for 循环以及 j.u.c.Stream 的性能。
普通 Java for 循环代码如下:
@Benchmark
public void javaRange(Blackhole bh) {
int n = times;
for (int i = 0; i < n; i++) {
bh.consume(i);
}
}
@Benchmark
public void javaRangeFlatMapJust(Blackhole bh) {
int n = times;
for (int i = 0; i < n; i++) {
for (int j = i; j < i + 1; j++) {
bh.consume(j);
}
}
}
@Benchmark
public void javaRangeFlatMapRange(Blackhole bh) {
int n = times;
for (int i = 0; i < n; i++) {
for (int j = i; j < i + 2; j++) {
bh.consume(j);
}
}
}
Stream 的测例写起来稍微复杂一些,因为 j.u.c.Stream 无法复用,我们每次都需要重新创建:
@Benchmark
public void streamRange(Blackhole bh) {
values.stream().forEach(bh::consume);
}
@Benchmark
public void streamRangeFlatMapJust(Blackhole bh) {
values.stream()
.flatMap(v -> Collections.singletonList(v).stream())
.forEach(bh::consume);
}
@Benchmark
public void streamRangeFlatMapRange(Blackhole bh) {
values.stream()
.flatMap(v -> Arrays.asList(v, v + 1).stream())
.forEach(bh::consume);
}
最后,为了好玩,我们做一个 Stream 并发版的测试:
@Benchmark
public void pstreamRange(Blackhole bh) {
values.parallelStream().forEach(bh::consume);
}
@Benchmark
public void pstreamRangeFlatMapJust(Blackhole bh) {
values.parallelStream()
.flatMap(v -> Collections.singletonList(v).stream())
.forEach(bh::consume);
}
@Benchmark
public void pstreamRangeFlatMapRange(Blackhole bh) {
values.parallelStream()
.flatMap(v -> Arrays.asList(v, v + 1).stream())
.forEach(bh::consume);
}
好了,让我们看看结果:
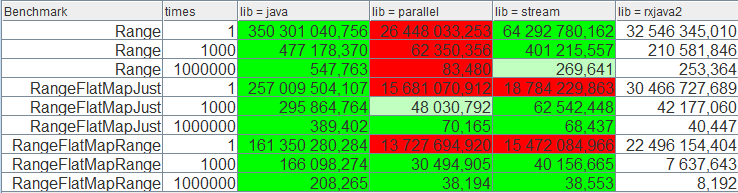
除了在几种并发的情形下,Java/Stream 的性能非常突出!在并发的情形下,我推测 forEach 把所有的并发操作同步到单个线程了,这就丢掉了所有的优势。
总结一下,如果我们有同步的任务,先试试基本的 Java 循环。
总结
在本文中,我在同步场景下,对三个 Reactive-Streams 库的易用性和性能进行了对比测试。相比于纯 Java,RxJava 和 Reactor 都做得不错,但 Akka-Streams 用起来则相当麻烦,而且性能也令人失望至极。

但是也不排除 Akka-Streams 在下篇的异步场景中能有所表现。